https://arxiv.org/pdf/1603.06937.pdf Stacked Hourglass Networks for Human Pose Estimation
논문을 참고하여 작성하였다.
시작에 앞서 Human pose estimation의 2가지 방식인 top-down 방식과 bottom up 방식에 대해 정리해보자.

1. Top-down 방식 : 사람을 먼저 감지한 후 다음 각 사람의 자세를 추정한다.
2. Bottom-up 방식 : 관절 부위(key point)를 먼저 감지하여 서로 연결해 모든 사람의 자세를 추정한다.
Stacked Hourglass
Stacked Hourglass는 single person의 pose를 예측하는 모델이고, 모래시계를 쌓아둔 모양을 가진 네트워크이다.
이미지의 모든 scale에 대한 정보를 downsampling 과정에서 추출하고 이를 unsampling 과정에 반영하여 pixel-wise output 을 생성하는 것을 목표로 하며, Hourglass module을 연속하여 잇는 방식인 Stacked hourglass Network 구조를 사용한다. 이 구조는 여러 scale에 대해 반복적인 bottom-up, top-down inference를 가능하게 한다.

Architecture
최종적으로 pose를 추정하기 위해서는 전체 body에 대한 이해가 매우 중요하다. 따라서 여러 scale에 걸쳐 필요한 정보를 포착해낼 수 있어야한다.
Hourglass는 모든 feature들을 잡아내어 network의 출력인 pixel 단위의 예측에 반영되도록 한다. Skip layer를 이용한 단 1개의 pipline 만으로 spatial information을 유지하는 방식을 채택한다.
Feature 추출과 저차원으로의 downsampling을 위해 convolutional & pool layer를 사용한다. 매 MaxPooling 단계에서 입력을 별도의 branch로 내보내고 이에 convolutional 연산을 적용한다. 따라서 scale마다 feature가 추출된다.
가장 낮은 resolution에 도달하면 upsampling 과정을 통해 scale별로 추출한 feature들을 조합해준다.
Network의 출력값으로는 각 관절에 대한 추정(확률) 값이 담긴 heatmap을 추출한다.
Q. Upsampling / Downsampling?
downsampling으로 sampling을 진행하면 데이터의 크기가 작아진다.
예를들어 HxW가 5x5 인 이미지를 3x3 으로 convolution sampling을 진행할경우, HxW 가 3x3 이미지로 바뀌는것 처럼 convolution을 통하면 이미지 크기가 작아졌다. 이러한 sampling 방식을 down sampling이라고 한다.
Upsampling은 downsampling과 반대로, sampling을 통해 데이터의 크기를 키우는 것이다.
(1) Single Hourglass

Single Hourglass는 아래의 그림과 같다. 사진의 각 box들은 위 왼쪽 그림과 같은 residual unit을 의미한다. 3x3 크기 이상의 filter를 사용하지 않았고 memory 사용량을 줄이기 위해 bottleneck 구조를 사용하였다.
위 왼쪽 그림은 Hourglass 안에서 사용하는 residual module이고 이를 통하여 down sample 과정을 거친다. 아래 사진과 같이 최소 resolution에 도달한 뒤에 bilinear upsmaple 방식으로 원래 input값의 크기로 복원해준다. 또한 동일한 크기의 resolution끼리 element wise 하게 더해주는 연산을 수행한다.

이와 같은 과정을 거치게 되면 최소 resolution이 지니고 있는 얼굴, 손과 같은 local 정보와 원래 입력 크기가 지니고 있는 몸 전체와 사람의 방향, 팔의 형태를 함께 이용할 수 있다.
다음 사진은 input과 output 에 대한 정보를 정리한 사진이다.

(2) Intermediate Supervision

Stacked Hourglass Networks는 다수의 Hourglass Network를 쌓아 놓은 구조이다. 반복적인 bottom-up, top-down inference 를 가능하게 하며, 이를 통하여 initial estimate과 이미지 전반에 대한 feature를 다시금 추정(reevaluation)할 수 있게 한다.
이전 hourglass 출력값에 1x1 conv를 거쳐서 두 개의 branch로 나뉘어 진다. 하나는 heatmap을 생성하고, 다른 branch는 다음 hourglass module에 입력되기 위한 과정을 거친다. heatmap에서 loss를 계산한 뒤에 1x1 conv 연산을 수행하여 채널 수를 조정한다. 다음 hourglass module에 입력되기 전에, 3개의 값이 addition 연산을 통해 하나의 값으로 결합된다.
중요한 것은, 중간 중간 얻어지는 예측값(prediction of intermediate heatmaps)에 대해서도 ground truth 와의 loss 적용(intermediate supervision)이 가능하다.
반복적인 예측값의 조정으로 좀 더 세밀한 결과를 도출할 수 있으며, 중간에 적용되는 loss로 인해 좀 더 깊고 안정적인 학습이 가능하다.
※ 주의!
- Hourglass Module간 weight 공유 x
- Loss 계산 시 모든 hourglass 들의 prediction에 대해 동일한 ground truth 사용
- multi person의 경우 중간에 위치한 인간을 예측하는 경향을 보인다.
Network 출력 (output) 값
Network의 출력값을 보여주는 사진이다. 가장 왼쪽에 final pose estimate이 heatmap을 통해 제공된 것을 볼 수 있다. 오른쪽 사진들은 smaple heatmap 들이다.

Performance
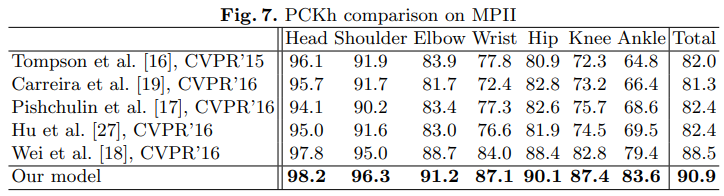
다른 모델들보다 뛰어난 성능을 보여준다.
reference : https://memesoo99.tistory.com/31, https://beyondminds.ai/blog/an-overview-of-human-pose-estimation-with-deep-learning/
'논문 리뷰 > Human Pose estimation' 카테고리의 다른 글
| [논문 리뷰] Human Pose Estimation for Real-World Crowded Scenarios (0) | 2022.04.14 |
|---|---|
| [논문 리뷰] Higher HRNet (0) | 2022.04.02 |
| [논문 리뷰] HRNet (0) | 2022.04.02 |
| [논문 리뷰] Convolutional Pose Machine (0) | 2022.04.02 |




댓글