https://arxiv.org/pdf/1902.09212.pdf Deep High-Resolution Representation Learning for Human Pose Estimation
논문을 참고하여 작성하였다.
Abstract
HRNet은 single person의 pose를 예측하는 모델이고, 본 논문에서 제공하는 network는 높은 해상도를 전체 프로세스 동안 유지하는 특징을 가지고 있다.
: maintains high reoslution representations through whole process
High resolution subnetwork를 시작으로 점점 stage 추가를 위해 high-to-low resolution subnetwork를 추가하며, multi resolution subnetwork를 "parallel"하게 연결한다.
반복되는 multi-scale fusions를 구성하여 각각의 resolution이 다른 parallel representation으로부터 정보를 계속해서 얻을 수 있게끔 해준다. 결과적으로 이런 방식을 통해 keypoint heatmap의 좀 더 세밀하고 정확한 결과가 나온다.
Introduction
human pose estimation은 keypoint들의 위치를 예측하는데에서부터 시작한다. 이 논문은 single person pose estimation에 초점을 두고 있다.
현존하는 methods 들 경우 input 값은 network (series하게 연결된 high-to-low resolution subnetwork)를 통과하면서 그 이후에 low-to-high resolution subnetwork를 통해 resolution을 증가시킨다. 따라서 아래 사진과 같이 high resolution이 계속 유지되는 구조가 아닌, 낮은 resolution으로 갔다가 다시 high resolution으로 복구되는 구조들을 지닌 methods들이 대부분이었다.
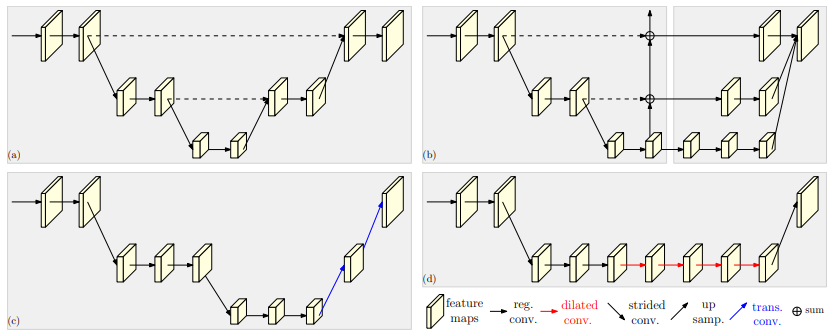
HRNet
본 논문은 새로운 구조 "HRNet"을 선보이는데, 앞서 말했듯 모든 process에서 high resolution을 유지하는 구조를 지닌다.
첫번째 stage에서 high resolution subnetwork에서 시작하여, 점진적으로 high-to-low resolution subnetwork를 추가하고 parallel하게 multi-resolution subnetworks들을 연결한다.
Q. Parallel하게 적용?
기존 : Input받은 strand가 downsample 된다.
HR : Input 받은 strand의 해상도는 쭉 유지가 되고 거기서 평행하게 downsample되는 strand가 분리된다.
반복적으로 multi-scale fusions를 구성하여, 전체적인 process 동안 parallel하게 연결된 multi-resolution subnetworks간 정보를 교환해준다.
최종 예측은 아래 그림과 같이 (맨 위 resolution에만 → 화살표 존재) 가장 높은 resolution representations output으로만 한다.
Q. 왜 가장 높은 resolution representation에 대해서만 최종 output값으로 내놓을까..?
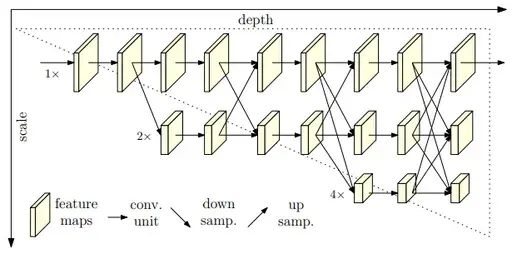
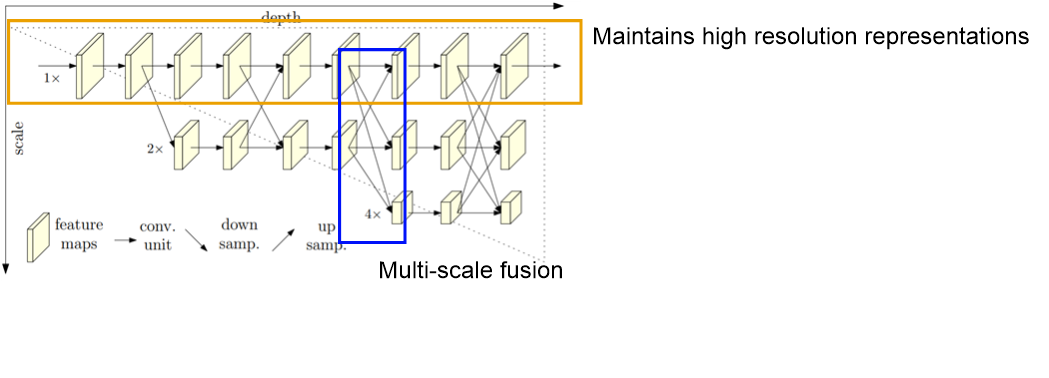
다른 network에 비해 HRNet network가 가진 이점이 2가지 존재한다.
1. Connection of high to low resolution is in parallel not in series
→ maintain high resolution without recovering by low-to-high process
→ heatmap precise
high-to-low resolution의 연결이 parallel하게 되어 있기 때문에, process 내내 높은 해상도를 유지할 수 있어 low-to-high process가 불필요하다. 이로인해 heatmap이 더 세밀하게 추출된다.
2. Repeat multi scale fusions to boost the high-resolution representations with the help of the low-resolution representations of the same depth and similar level
multi scale fusion을 반복적으로 사용하여 같은 depth, 비슷한 level의 low-resolution이 high resolution representation을 지원해주도록 한다. 즉, parallel한 sub-network 간에 정보를 계속 주고 받는다.
따라서 heatmap의 정확도가 올라간다.
Related work
(1) Multi-scale fusion
Multi-resolution 이미지들을 각각 따로 multiple networks에 넣고 각각의 output response maps들을 aggregate한다.
(2) Intermediate supervision
중간에 loss를 계산하는 intermediate supervision은 deep netwrok 학습에 도움이 되고, heatmap 예측의 질을 높여주어 많이 사용되었다. Hourglass 나 CPM의 경우 intermediate heatmap을 다음 stage의 input값으로 넣기도 하였다.
(3) Our approach
HRNet은 앞서 계속 언급했듯, high-to-low subnetworks를 parallel하게 연결하여 high-resolution representations를 전체 process동안 유지시켜준다.
반복적으로 high-to-low subnetworks들의 representation을 fuse함으로써, high-resolution representation을 생성한다. 이로 인하여 개선된 heatmap estimation이 가능해진다.
차이점이 존재한다면, 분리된 low-to-high upsampling process가 필요하고 low-level 과 high-level representations들을 합쳐준다.
Intermediate supervision을 사용하지 않고서도 keypoint detection 정확도가 높고, 계산 복잡도에서도 효율적인 모습을 보여준다.
Approach
Human pose estimation (keypoint detection)은 W x H x 3 크기의 input 으로부터 K 개의 keypoint들을 detect하여 location을 파악하는 것을 목표로 한다.
(1) Pipline
1. Stem consisting of 2 strided convolutions decreasing the resolution
해상도를 낮추는 stride가 2인 convolution 으로 시작한다.
2. Main body outputting the feature maps with the same resolution as its input feature maps
Input feature maps과 해상도가 같은 output feature map을 생성하는 main body
3. A regressor estimating the heatmaps where the keypoint positions are chosen and transformed to the full resolution
keypoint 위치를 선정하는 heatmap을 예측하는 regressor
여기서 Main body는 HRNet(high resolution Net)을 사용한다.
(2) Sequential multi-resolution subnetworks
기존의 network은 high-to-low resolution subnetworks들을 series하게 연결하여 각 stage를 구성하는 subnetwork들은 convolutions들로 구성되어 있고, resolution을 반으로 낮추는 down-sample layer가 adjacent subnetworks에 존재했다.
여기서 첫번째 인자는 stage, 두번째는 resolution index라 한다. (첫번째 resolution보다 1/2^(r-1) resolution을 지님)
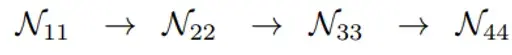
따라서 high to low network stages는 위와 같이 나타낼 수 있다. (series하게 연결)
(3) Parallel multi-resolution subnetworks
high-resolution subnetwork으로 first stage를 시작하여 점진적으로 high-to-low resolution subnetworks를 stage별로 하나씩 추가하고, multi-resolution subnetworks들을 parallel하게 연결한다.
따라서 결과적으로 나중의 stage의 resolution은 이전 stage의 resolution과 lower one으로 구성되어 있다.
예를들어, 4개의 parallel한 subnetwork을 지닌 network structcure를 보면 다음과 같다.
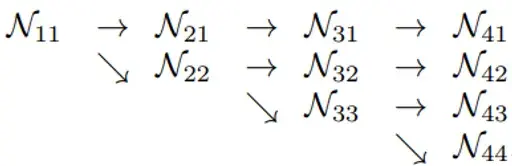
따라서 정리하자면,

(4) Repeated multi-scale fusion
Exchange units across parallel subnetworks : 다양한 scale을 반복적으로 fusion하는 과정에서 Exchage Unit이란게 사용된다. 예를들어 맨 왼쪽 그림에서, 가장 높은 resolution에 정보를 주기위해 2, 3 번째 resolution은 1x1 upsampling을 거쳐 정보를 전달한다.

서로다른 resolution의 정보를 합칠 때는 적절하게 upsampling/downsampling하는 것이 필요하다. 아래 그림은 stage 3를 여러 exhange block으로 나눈 그래프이다.
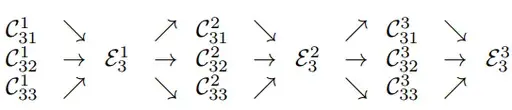
3번째 stage를 3개의 exchange blocks로 나누었고 각각의 block은 3개의 exchange units와 함께 parallel convolution units 로 구성되어있다.

여기서 a(X_i,k)의 a( )함수는 resolution을 i에서 k로 변환시키는 것을 의미한다. 따라서 1부터 s까지 k로의 resolution 변환을 구하여 합한것을 Yk 라고한다.
With Code
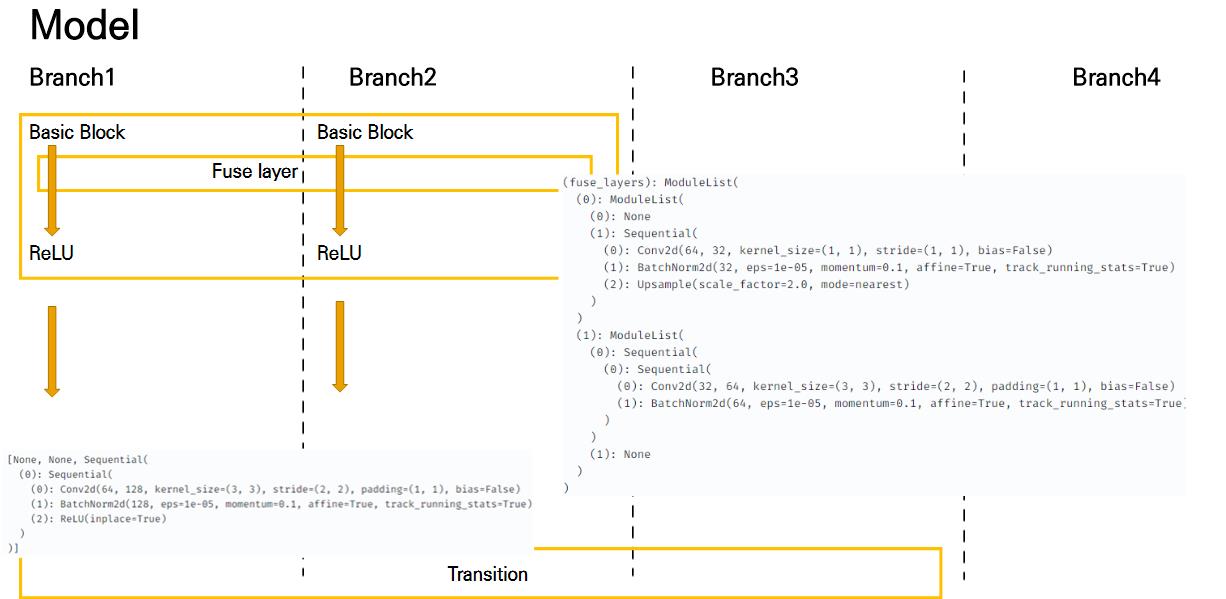
Model의 stage1과 stage2만 살펴보면 다음과 같다.
2개의 convolution layer로 시작하여 bottleneck을 지나 첫번째 resolution을 생성한다. 이후 Transition layer에서 2번째 branch/ 2번째 resolution을 생성한다.

Branch 별로 block들을 통과 한 뒤 Multi fuse layer를 통해 branch1의 high resolution과 branch2의 resolution이 서로 정보를 교환할 수 있도록 차원수를 조정해준다.
이후 stage2에서도 transition layer를 통해 3번째 branch, resolution을 생성하게 된다.
Heatmap Estimation
최종적으로 heatmap은 Last exchange unit Ys+1 으로부터 나온 high-resolution representations output 으로 regress한다.
Loss Function은 평균 제곱 오차 MSE를 사용한다. 여기에 사용되는 GT heatmap은 각 keypoint에 2D 가우시안 분포를 적용해서 구한다.
Experiment
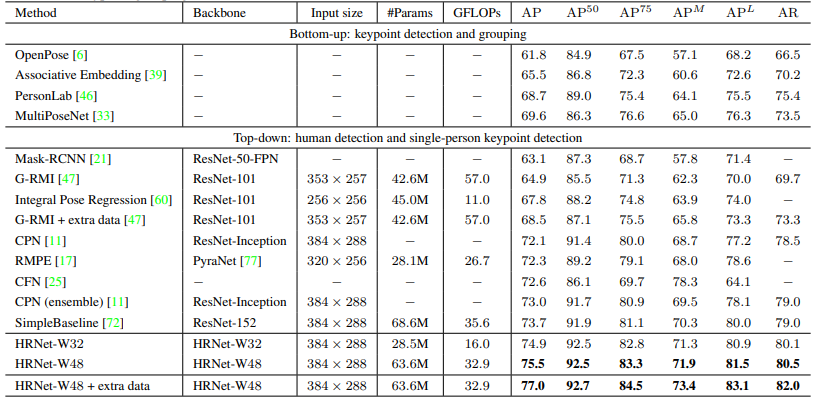
reference : https://memesoo99.tistory.com/31
'논문 리뷰 > Human Pose estimation' 카테고리의 다른 글
| [논문 리뷰] Human Pose Estimation for Real-World Crowded Scenarios (0) | 2022.04.14 |
|---|---|
| [논문 리뷰] Higher HRNet (0) | 2022.04.02 |
| [논문 리뷰] Stacked Hourglass (0) | 2022.04.02 |
| [논문 리뷰] Convolutional Pose Machine (0) | 2022.04.02 |




댓글