https://arxiv.org/pdf/1602.00134.pdf Convolutional Pose Machines
논문을 참고하여 작성하였다.
이번 논문은 Human pose estimation에 관련된 Convolutional Pose Machine이다. CNN이 Human pose estimation에 적합한 이유로는 관절 위치 예측시 이미지 맥락을 파악하여 예측하는 것이 가능하기 때문이다. 따라서 관절 간의 상관관계를 학습하여 더 좋은 예측 값을 추출 할 수 있다.
CPM 모델은 Pose machine + CNN 으로, receptive fied(지역적 정보) 를 global한 영역을 확대하여 다른 부위와의 관계를 고려한 모델이다.
CPM Model

먼저 CPM은 각 stage에서 multi-class classifier(CNN)을 이용하여 각 part(관절)에 해당되는 belief map을 위와 같이 추정한다. 그리고 각 stage에서 추정한 belief map의 정보는 fine tuning을 위해 다음 stage로 전달이 된다. 따라서 stage를 계속 밟을 수록 더 명확한 예측이 나오는 것을 확인할 수 있다. 위 사진과 같이 stage1은 input image에 대해 정확한 예측을 못하는 반면, stage3에서는 좀 더 명확한 예측값을 보여준다.

CNN 하위 layer에서는 local(지역 정보)한 영역을 해석하고 상위로 갈 수록 receptive filed 이 커지면서 global한 영역을 해석하는 것을 확인할 수 있다. 해석된 정보는 각 stage를 구성하는 CNN의 feature map에 저장된다.
(1) Pose Machine
p 개의 관절에 대하여 Human pose estimation의 목표는 Y = ( Y1 , ... , Yp) 의 좌표를 예측하는 것이다. 각 stage에 대해 classifiers g_t 함수는 belief map을 예측한다.
Image의 모든 위치 (u,v) 를 포함하는 Z 집합에 대해 g_t 함수는 z( = Yp) 위치 예측을 위해 z 위치에서 추출한 features x_z 와 Yp 주변에서 얻은 contextual 정보를 사용한다.
따라서 아래와 같은 방식으로 stage1의 belief map을 생성한다.

각 part마다 score map이 존재하고, 아래 식은 t stage에서 이미지의 z location에서의 p 번째 관절에 대한 score라고 정의한다. score 가 높으면 해당 z location에 p번째 관절이 위치할 확률이 높다고 해석할 수 있다.

t stage의 경우 Input image의 feature 정보다 t-1 stage에서 예측된 score b_t-1 를 concatnate하여 t stage에서의 belief map을 생성하게 된다.


위 사진은 stage 별로 input image가 지나는 layer와 belief map이 생성되는 과정과 belief map이 context feature로 전환이 되어 그 다음 stage에서 concate 되는 과정을 보여준다.
(2) Intermediate supervisions
중간 layer에 손실을 강제 삽입하는 구조로 즉, stage 마다 loss insertion을 통해 gradient vanishing problem을 방지한다.
다음 그림은 intermediate supervision 유무에 따른 gradient의 변화이다. Intermediate supervision이 없는 경우 gradient가 0의 값에서 거의 벗어나지 않아 gradient vanishing problem을 지니지만, 각 stage 별로 loss를 계산하는 intermediate supervision을 적용하는 경우 0을 벗어나는 형태를 보인다.

(3) Loss function
각 stage에서 각 part의 ground truth belief map과 추정한 belief map의 L2 norm을 손실함수로 설정해준다. 최종 loss function은 모든 stage의 cost funtion을 합으로 정의한다.

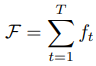
Conclusion
고정된 part인 목, 허리, 어깨에 대한 검출은 좋으나 팔 다리 limb과 같이 검출이 힘든 부분의 결과는 변동이 심하다. 하지만 part간의 consistent geometry가 있어 고정적인 부분이 변동 부분에 대해 cue를 주기 때문에 보완할 가능성이 있다. 이를 위해서는 receptive field가 넓어 global 한 영역에서 상관관계를 파악할 수 있어야한다.
'논문 리뷰 > Human Pose estimation' 카테고리의 다른 글
| [논문 리뷰] Human Pose Estimation for Real-World Crowded Scenarios (0) | 2022.04.14 |
|---|---|
| [논문 리뷰] Higher HRNet (0) | 2022.04.02 |
| [논문 리뷰] HRNet (0) | 2022.04.02 |
| [논문 리뷰] Stacked Hourglass (0) | 2022.04.02 |




댓글