Deep Residual Learning for Image Recognition
https://arxiv.org/pdf/1512.03385.pdf 논문을 참고하여 작성하였다.
Introduction
저번 VGGNet에서 CNN의 layer가 깊어질수록 성능이 좋아지는 것을 확인할 수 있었지만, VGGNet-19에서 오차율이 떨어지지 않는 것을 확인할 수 있었다. Layer가 더 깊어지면 Vanishing/Exploding gradient 현상이 발생하는데, 정확도가 어느 순간 정체되고 layer가 깊어질수록 성능이 더 나빠지는 현상인 Degradation problem이라는 문제점이 발생하게 된다.
Vanishing/Exploding gradient의 경우 layer 중간에 BatchNorm 을 적용해주면 해결할 수 있다.
Q. Vanishing / Exploding gradient?
Vanishing gradient란 backpropagation 과정에서 gradients들이 점점 작아지다가 0에 수렴하게 되는 현상을 말한다. Input layer에 가까운 층들에서 가중치들이 제대로 update 되지 않으면 최적의 모델을 찾기 어렵게 된다.
반대로 exploding gradient는 backpropagation 과정에서 gradient가 점점 커져 발산하는 현상을 말한다.
본 논문에서는 Residual Learning을 통해 Degradation 문제를 해결하고자 한다. Deep Residual Learning이라고도 하며 이 model은 일반적인 layer만 깊은 모델들과 비교시 뛰어난 성능을 자랑하며 빠른 학습 속도를 지닌다.
Deep Residual Learning
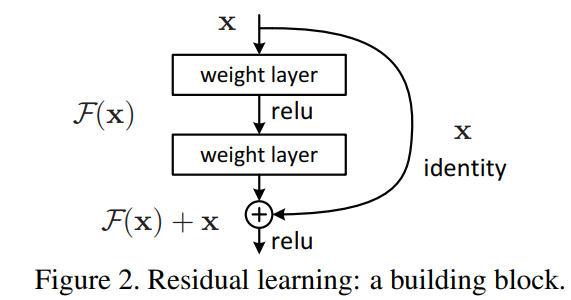
위 사진은 Residual Learning의 Basic Block 형태를 보여준다.
- Input 값 x를 받아 layer들을 통과하여 F(x)라는 값을 추출해낸다.
- layer를 통과하지 않은 input 값 x 를 identity x로 정의한다.
- Identity x 와 F(x)을 더해주어 최종 값 F(x) + x를 추출한다.
여기서 identity x는 layer를 통과하지 않고 더해주기 때문에 'Skip Connection'이라고 칭한다.
Identity x와 layer를 통과한 x 의 결괏값인 F(x)를 더해줄 때 문제점이 발생한다. 만약 identity x의 차원과 F(x)의 차원이 같다면 문제가 없지만, 다르다면 더해줄 수 없다는 것이다. 따라서 identity x의 차원을 조절해주어야 한다.
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
위 코드는 Basic Block의 forward 함수와 self.shortcut이 정의된 것을 보여준다. Forward 함수에서 알 수 있듯 weight layer를 통과한 input x 값을 out으로 정의하고, layer 를 skip 한 input x 값을 마지막에 out과 함께 더해준다.
만약 x와 out의 차원이 다르다면 즉 stride값이 1이 아니라면 self.shortcut를 통해 x를 out과 같은 차원으로 맞추고 난 후에 더해준다.
Q. 왜 Skip connection을 하면 더 좋은 성능을 보여줄까?
layer를 통과한 input값과 layer를 통과하지 않은 본연의 input값을 합쳐 더 많은 정보를 지니기 때문?
Network Architectures and Implementation
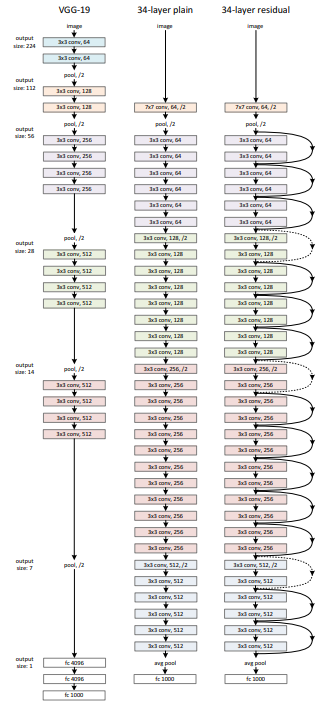
ResNet의 기본 구조는 VGGNet-34를 따른다. 아래 그림과 같이 VGGNet-34와 모델 구성은 같지만 두개의 layer마다 skip connection을 해준다는 것을 알 수 있다. 점선으로 표시된 skip connection의 경우는 input x와 F(x) 값의 차원이 달라 dimension을 맞춰주는 작업을 한 skip connection들을 의미한다.
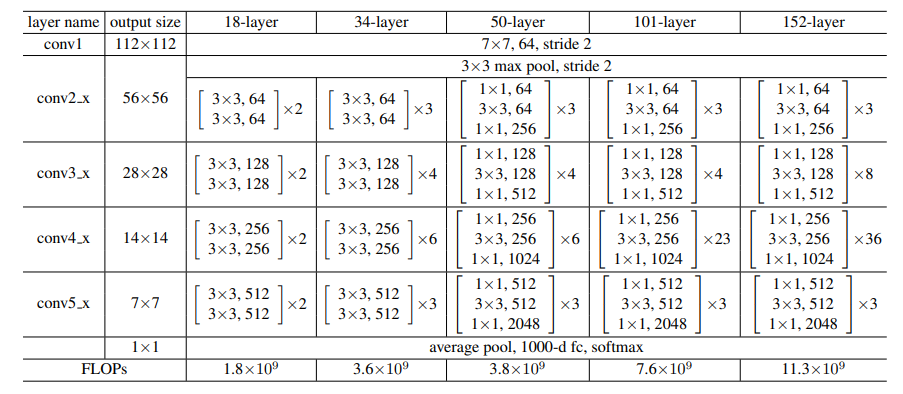
아래 그림은 ResNet의 layer 깊이에 따른 구조를 요약한 table이다. 공통적으로 7x7/64/stride 2 와 3x3 maxpool/stride 2 layer 들을 통과하는 것을 시작으로 한다. 34-layer의 경우 3x3 conv/64 layer가 2개 존재하는 block이 총 3개, 3x3 conv/128 layer가 2개 존재하는 block이 총 4개, 3x3 conv/256 layer가 2개 존재하는 block이 총 6개, 3x3 conv/512 layer가 2개 존재하는 block이 총 3 개로 이루어져있는 것을 확인할 수 있다. 마지막 average pool, FC, softmax를 공통적으로 통과한다.
Experiments
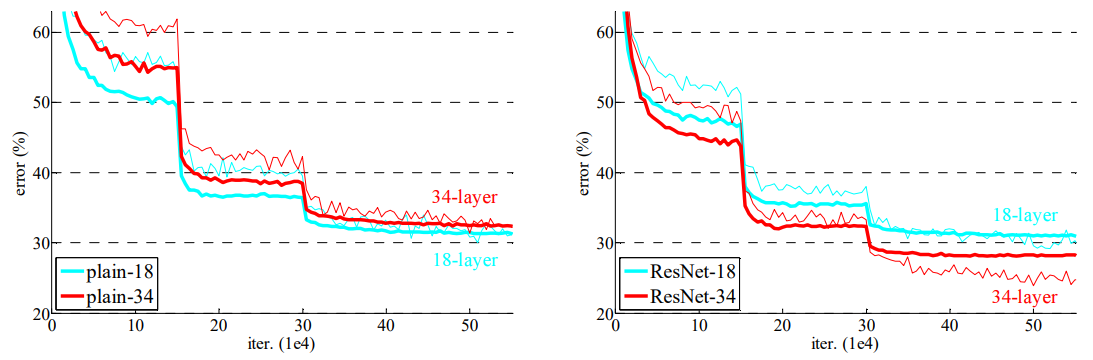
위 그림을 통해 ResNet-18 과 ResNet-34가 plain-18과 plain-34보다 더 좋은 성능을 보이고 있음을 알 수 있다. 또한 왼쪽 그림에서는 plain-34가 plain-18보다 loss값이 큰 것을 보아 Degradation 문제점이 보이지만 오른쪽 그림은 ResNet-34 가 ResNet-18보다 loss 값이 작은 것을 보아 Degradation 문제가 해결된 것을 알 수 있다.
Deeper BottleNeck Architectures
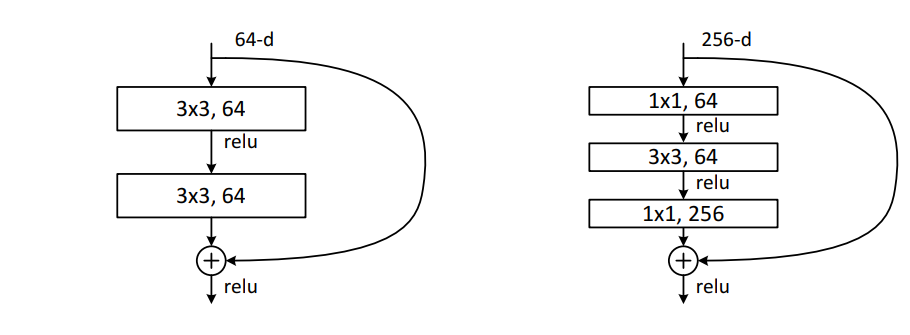
Network의 깊이가 50을 넘어가게 되면 ResNet과 3x3 filter만 사용한다 할지라도 training 시간이 매우 길어진다는 단점이 있다. 따라서 이 경우 원래 model 구조에서 약간의 수정이 필요하다.
위 그림과 같이 3x3 filter를 두번 사용하는 대신, 1x1 → 3x3 → 1x1 필터를 사용하는 구조를 만든다. 이 구조는 dimension의 크기를 줄일 뿐 아니라 시간 복잡도도 줄이는 효과를 보여준다. 따라서 더 깊은 구조를 구현할 수 있다.
Q. 1x1 convolution?
1x1 Convolution에는 크게 세 가지 장점이 있다.
- Channel 수 조절
- 연산량 감소(Efficient)
- 비선형성(Non-linearity)
1. Channel 수 조절
Channel 수는 하이퍼 파라미터이기 때문에 본인이 직접 결정해야 하는데, 1x1 convolution의 경우 기존 정보를 변형하지 않고 channel 수만 바꿀 수 있는 장점을 가진다.
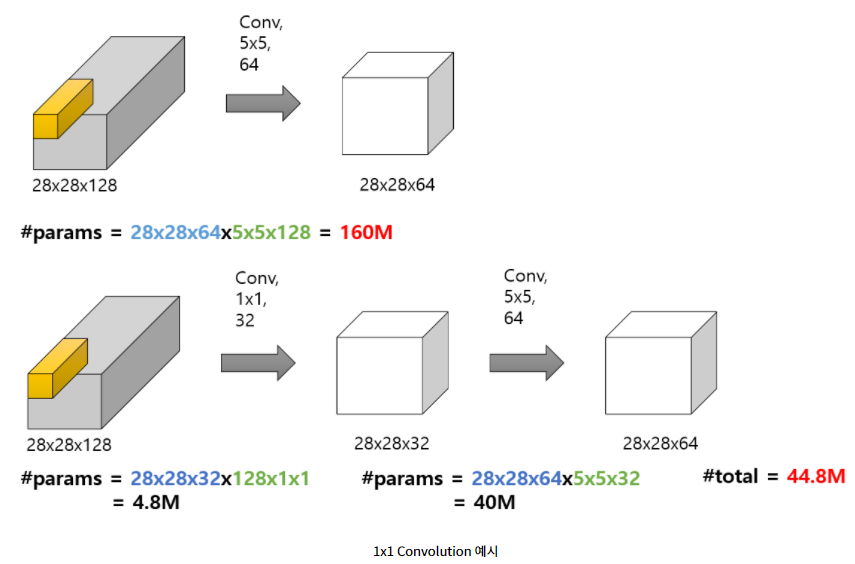
2. 연산량 감소
아래 그림과 같이 5x5 convolution을 적용한 것과 1x1 convolution을 적용 한 후의 계산량 차이가 있음을 알 수 있다.
Conclusion
ResNet은 Degradation 문제를 Identity Mapping을 통해 해결하였고, network가 빨리 수렴할 수 있도록 training 시간도 단축시켰다. Block이라는 개념을 ResNet에서 처음 접하게 됐는데 반복적인 layer를 간단하게 표현할 수 있는 이 개념은 이후 논문에서 많이 사용된다. Block 형태 없이 논문이 구현될 수 없을 정도로 이 개념은 굉장히 획기적이었다는 것..!
reference : https://jays0606.tistory.com/3, https://hwiyong.tistory.com/45
'논문 리뷰 > Classification' 카테고리의 다른 글
| [논문 리뷰] MobileNetV1 & MobileNetV2 (0) | 2022.04.02 |
|---|---|
| [논문 리뷰] VGGNet (0) | 2022.03.30 |


댓글