https://arxiv.org/pdf/1801.04381.pdf MobileNetV2: Inverted Residuals and Linear Bottlenecks
https://arxiv.org/pdf/1704.04861.pdf MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
위 논문을 참고하여 작성하였다.
MobileNetV1
MobileNetV1은 light weight deep neural network, depthwise separable convolution을 통해 모델 경량화에 집중하였다.
모델 경량화에 집중한 이유로는 저용량 메모리 환경인 핸드폰과 같은 곳에 딥러닝을 적용하기 위해서이다. 메모리가 제한된 환경에서 MobileNet을 최적으로 맞추기 위해서는 2개의 파라미터의 균형을 조절하는데, 이는 latency(지연 시간)과 accuracy이다.
먼저 MobileNet이 경량화를 성공하게된 가장 큰 이유였던 모델의 구조를 이해하기 위해 Depthwise separable convolution에 대해 알아보자.
(1) Depthwise Convolution
Depthwise convolution은 각각의 입력 채널에 대하여 3x3 convolution 하나의 필터를 이용하여 연산 수행 후 하나의 feature map을 생성한다. 입력 채널 수가 M이면 M개의 feature map을 생성하는 샘이다. 각 채널마다 독립적으로 연산을 수행하여 spatial correlation을 계산하는 역할을 한다.
예를들어, 5 channel의 input 값이 입력 되었으면, 5개의 3x3 convolution이 각 채널에 대하여 연산을 수행하고 총 5개의 feature map이 생성된다.
Depthwise convolution의 연산량은 다음과 같다. D_k 는 kernel size, M은 입력 채널의 수, D_F는 feature map의 크기이다.
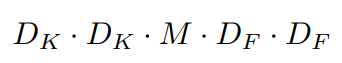
(2) Pointwise convotluion
Pointwise convolution은 Depthwise convolution이 생성한 feature map들을 1x1 convolution으로 channel의 수를 조정하는 역할을 해준다. 동시에 1x1 convolution은 모든 채널에 대해 연산을 하기 때문에, cross-channel correlation을 계산하는 역할을한다.
Pointwise convolution 연산량은 다음과 같다. M은 input 채널 수, N는 output 채널 수, D_F 는 feature map 크기이다.
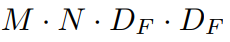
(3) Depthwise Separable convolution
Depthwise separable convolution은 Depthwise convolution 후에 pointwise convolution을 적용한 구조이다. 아래 그림은 MobileNet에서 사용하는 Depthwise separable convolution 구조이다. 오른쪽은 Standard convolution layer + BatchNorm + ReLU 형태이고, 왼쪽 구조는 Depthwise Separable convolution 구조이다.

전체 연산량을 확인해보면,
Depthwise separable convolution의 경우는 다음과 같다.
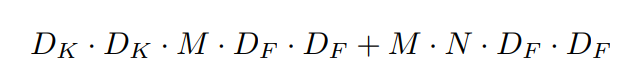
기존 Standard convolutional layer의 연산량은 다음과 같다.
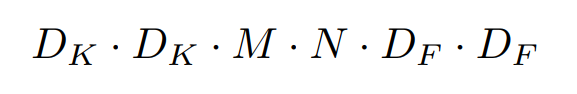
아래 그림과 같이 D_F x D_F 크기의 M개의 채널에 대하여 D_k x D_k 크기의 filter를 총 N개 연산한 Standard convolution filter와, 각 채널에 D_k x D_k 크기의 filter를 연산해준뒤 N개의 1x1 filter N개로 연산한 Depthwise separable convolution이다.
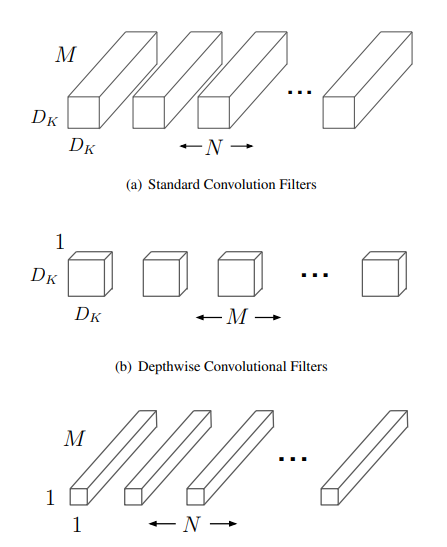

따라서 연산량은 다음과 같은 연산량만큼 줄어들어, 훨씬 가벼운 모델 구조를 지닌다.
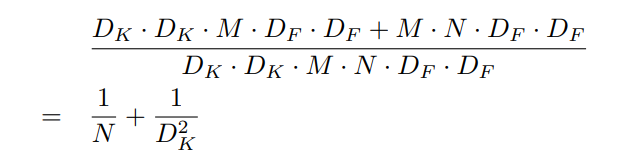
MobileNetV2
MobileNetV1의 Depthwise separable convolution에 대해 알아보았다. MobileNetV1을 이어 나온 MobileNetV2는 Depthwise separable convolution 를 수정한 구조를 제안한다. 수정된 구조인 Convolution Block은 Inverted Residuals와 Linear Bottlenecks를 사용하여 성능을 향상 시켜준다. 이 Block을 여러개 쌓은 모델을 MobileNetV2라고 칭한다.
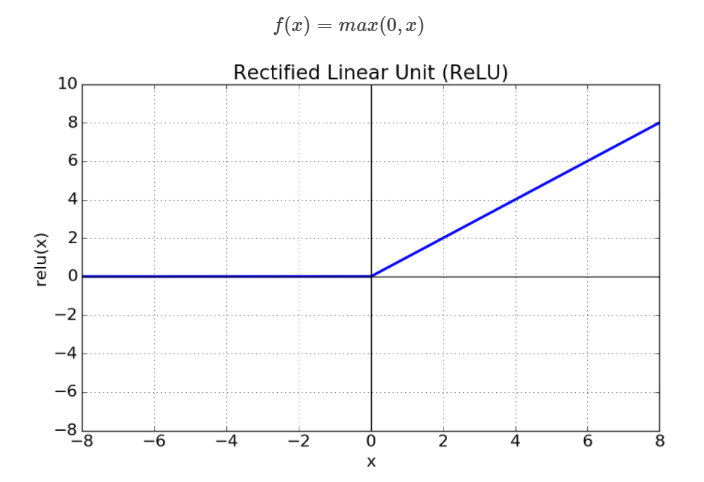
(1) Information Loss by ReLU
채널 수가 적은 입력 값이 ReLU 함수 계층을 거치게 되면 정보가 손실된다. ReLU 함수를 보면 알 수 있듯, 0 이하의 값은 사라지기 때문이다. 반면, 채널 수가 많은 입력 값은 ReLU 함수를 거쳐도 정보가 보존된다. 따라서 ReLU 함수를 사용할 때에는 해당 layer에 많은 채널 수를 사용하고, 만약 적다면 선형 함수를 적용해야한다.
정보 손실을 보완하기 위해 나온 것이 입력 값의 채널 수를 풍부하게 만들어주는 Inverted Residuals와 ReLU 함수 대신 Linear 함수를 적용하는 Linear Bottleneck이다.
(2) Convolution Block for MobileNetV2
MobileNetV2 에서 사용하는 convolution block에 대한 사진이고, 오른쪽은 block을 시각화한 사진이다.
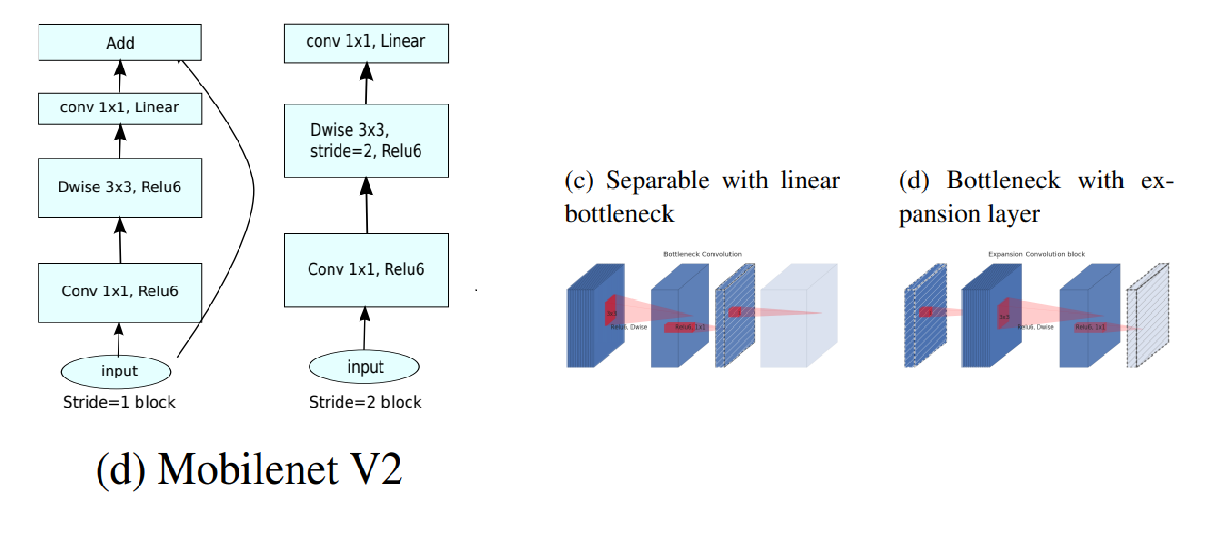
앞서 설명한 이유와 같이, 채널 수가 적은 입력값을 activation function ReLU 함수를 통과하게 되면 정보 손실이 발생하게 되어, 이를 방지하기 위해 ReLU함수를 Linear 함수로 바꾸는 Linear bottleneck과 입력 값의 채널 수를 증폭 시키는 1x1 expansion layer가 존재하는 Inverted bottleneck을 사용한다.
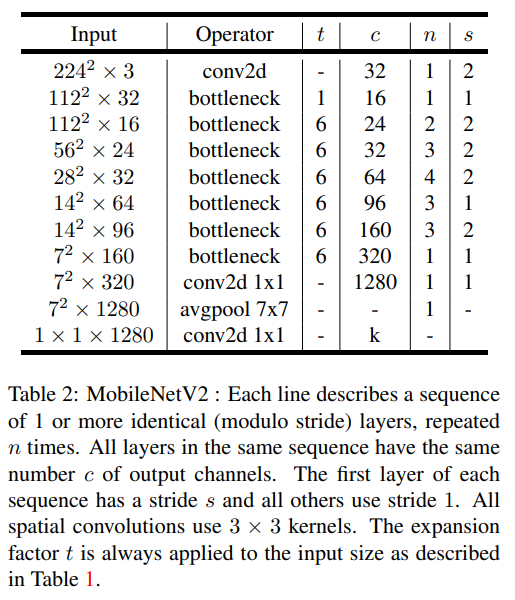
(3) MobileNetV2 Architecture
첫번째 layer는 일반적인 Conv2d layer를 사용한 후에 총 18개의 convolution block을 사용하였다.
stride의 경우 첫번째 layer에서는 s 값을 stride로 갖지만, 이후 layer에서는 1을 가진다.
- t : expansion factor
- c : output channel
- n : repeated times
- s : stride (first layer of each sequence has a stride s and all others use stride 1)
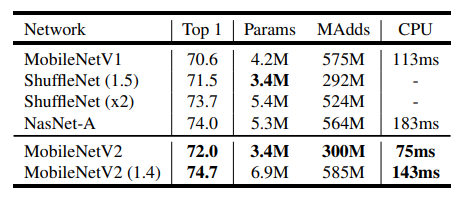
(4) Performance comparison
MobileNetV2가 다른 경량화 모델과 비교했을 때 좋은 성능을 보이고 파라미터 수도 적은 것을 확인 할 수 있다.
reference : https://deep-learning-study.tistory.com/541, https://www.researchgate.net/figure/a-The-process-of-standard-convolution-b-The-process-of-separable-convolution_fig2_334906706
'논문 리뷰 > Classification' 카테고리의 다른 글
| [논문 리뷰] ResNet (0) | 2022.03.31 |
|---|---|
| [논문 리뷰] VGGNet (0) | 2022.03.30 |


댓글