Code using mixup : https://github.com/shshin1210/cv-proj-withmixup/blob/main/README.md
Code using PENCIL : https://github.com/shshin1210/pencil_cifar100
Data : https://www.kaggle.com/c/cifar100-image-classification-with-noisy-labels/data
CIFAR100 image classification with Noisy Labels | Kaggle
www.kaggle.com
Kaggle에서 시행한 대회 중 Noisy Label이 있는 CIFAR100 데이터를 가지고 Image Classification 하고자 한다. Noisy label은 Kaggle에서 data 설명 부분에서 알 수 있듯, 학습 데이터 중 target label에 옳지 않은 값이 들어간 것을 의미한다.
※ Noisy Label ?
Symmetric noise : 10개의 class가 있다 가정했을 때, 각 라벨로 선택될 확률은 10%가 된다. 만약 원래의 clean label를 제외하고 계산한다면 이때는 1/9의 확률을 갖게 된다.
Asymmetric noise : Class-Dependent Noise로, noisy label로 바뀔 때 특정 클래스로 경향성을 보이는 Noise를 뜻한다. 예를들어, 고양이의 label이 개로 변경되는 것과 개로 되어있는 label 이 고양이로 변경될 경우이다.
Label noise가 있는 학습 데이터를 train하여 좋은 성능을 내기 위해 처음에는 Mix-up 기법을 사용하여 약 66%의 성능을 나타냈고, PENCIL 기법을 이용하여 약 68%의 성능을 낼 수 있었다.
부분적으로 코드 구현한 것을 살펴보자.
1. Data
먼저 데이터를 살펴보면,
dataset 파일 아래 cifar100_nl/data, cifar100_nl/img/test, cifar100_nl/img/train 폴더가 존재한다. Train, Test 폴더 안에는 train dataset, test dataset이 있으며 dataset의 이미지 파일 path와 label은 data 파일안 csv 파일에 존재한다.

아래와 같이 파일들을 정리하였고, dataset.py에 Custom Dataset을 구현하였다.
(proj_name)
├── dataset
│── dataset.py
│── data
│ │--cifar100_nl_test.csv
│ `-- cifar100_nl.csv
│
│── cifar100_nl/img
│-- test
│ │-- RvmEkKNaAS.png
│ │-- jsBXnkYbax.png
│ │-- tSGoIoLbQX.png
│ │-- ...
`-- train
│-- IGsDLlvWEG.png
│-- gzDCjnjiBq.png
│-- nGeAohKpVk.png
│-- ...
Custom Dataset
Custom Dataset을 직접 만들 때는 기본적으로 torch.utils.data.Dataset을 상속받아 구현한다. torch.utils.data.Dataset은 파이토치에서 데이터셋을 제공하는 추상 클래스로, pytorch DOCS를 참고하여 작성하면 많이 편하다!
https://pytorch.org/tutorials/beginner/basics/data_tutorial.html?highlight=torch%20utils%20data%20dataset
Datasets & DataLoaders — PyTorch Tutorials 1.11.0+cu102 documentation
Note Click here to download the full example code Learn the Basics || Quickstart || Tensors || Datasets & DataLoaders || Transforms || Build Model || Autograd || Optimization || Save & Load Model Datasets & DataLoaders Code for processing data samples can
pytorch.org
pytorch.org 에서 알 수 있듯, 데이터셋의 전처리를 해주는 부분 __init__( ), 데이터셋의 길이 즉 총 샘플의 수를 적어주는 부분은 __len__( ) 이며, __getitem__( ) 에서는 데이터셋에서 특정 1개의 샘플을 가져오는 함수에 해당하는 부분이다.
PENCIL 에서의 Custom Dataset 구현 방식과 Mix-Up 에서의 Custom Dataset 구현 방식이 약간 다르지만, PENCIL 을 기준으로 설명하려고 한다.
1) train, val 변수가 True False인가에 따라 train data, validation data, test data로 나누게끔 구현하였다. 또한, train dataset의 정보와 test dataset의 정보가 담긴 csv 파일이 달라 이를 나누어 csv_dir 로 정의 해주었다.
2) 39999를 기준으로 train dataset 과 validation dataset으로 나누었고, 각각의 이미지 파일 path와 label을 img_path 와 labels로 정의한다.
3) Hight/ Width/ Channel 순으로 reshape과 transpose 과정을 거쳐 데이터 전처리를 해준다.
4) __getitem__( ) 에서는 index 변수로 특정 1개의 샘플을 가져오는 함수를 정의해준다.
전체 코드는 아래와 같다.
from operator import index
from cv2 import transform
from matplotlib import transforms
import pandas as pd
from torch.utils.data import Dataset, DataLoader, random_split
from torchvision.io import read_image
import torchvision.transforms as transforms
import numpy as np
from PIL import Image
class C100Dataset(Dataset):
classes = ['apple', 'aquarium_fish', 'baby', 'bear', 'beaver', 'bed', 'bee', 'beetle', 'bicycle',
'bottle', 'bowl', 'boy', 'bridge', 'bus', 'butterfly', 'camel', 'can', 'castle', 'caterpillar', 'cattle',
'chair', 'chimpanzee', 'clock', 'cloud', 'cockroach', 'couch', 'crab', 'crocodile', 'cup', 'dinosaur',
'dolphin', 'elephant', 'flatfish', 'forest', 'fox', 'girl', 'hamster', 'house', 'kangaroo', 'keyboard',
'lamp', 'lawn_mower', 'leopard', 'lion', 'lizard', 'lobster', 'man', 'maple_tree', 'motorcycle', 'mountain',
'mouse', 'mushroom', 'oak_tree', 'orange', 'orchid', 'otter', 'palm_tree', 'pear', 'pickup_truck', 'pine_tree',
'plain', 'plate', 'poppy', 'porcupine', 'possum', 'rabbit', 'raccoon', 'ray', 'road', 'rocket', 'rose',
'sea', 'seal', 'shark', 'shrew', 'skunk', 'skyscraper', 'snail', 'snake', 'spider', 'squirrel', 'streetcar',
'sunflower', 'sweet_pepper', 'table', 'tank', 'telephone', 'television', 'tiger', 'tractor', 'train',
'trout', 'tulip', 'turtle', 'wardrobe', 'whale', 'willow_tree', 'wolf', 'woman', 'worm']
def __init__(self, train = True, val = False, transform = None ):
super().__init__()
self.csv_dir = './dataset/data/cifar100_nl.csv' if train else './dataset/data/cifar100_nl_test.csv'
self.transform = transform
dataset = pd.read_csv(self.csv_dir, names = ['filename', 'classname']) # 59998 / 9999
self.train = train
self.val = val
# train set
if train == True and val == False:
# trainset '/train/'
dataset = dataset[:39999]
# val set
if train == True and val == True:
dataset = dataset[40000:49999]
# img paths
self.img_paths = dataset['filename']
# img_labels
labels = dataset['classname']
self.data = []
if (train == True and val == False) or (train == False):
for i in range(len(dataset)): #train 39999, test 9999
img_path = './dataset/' + self.img_paths[i]
image = read_image(img_path)
self.data.append(image)
else:
for i in range(40000,49999): # val 9999
img_path = './dataset/' + self.img_paths[i]
image = read_image(img_path)
self.data.append(image)
# reshape & transpose to h/w/c
self.data = np.concatenate(self.data)
self.data = self.data.reshape(len(dataset), 3,32,32)
self.data = self.data.transpose((0,2,3,1))
self.img_labels = []
for label in labels:
self.img_labels.append(C100Dataset.classes.index(label))
def __len__(self):
return len(self.img_labels)
def __getitem__(self, index):
image, label = self.data[index], self.img_labels[index]
image = Image.fromarray(image)
if self.transform:
image = self.transform(image)
if self.train == True and self.val == False:
return [image, label, index]
else:
return [image, label]
2. Mix-Up
아주 간단하게 블로그에 mixup 에 대해 정리해놓은 글이다. 더 많은 내용은 논문을 참고하면 좋을 것 같다!
논문 : mixup BEYOND EMPIRICAL RISK MINIMIZATION, https://arxiv.org/pdf/1710.09412.pdf
blog 주소 : https://shshin9812.tistory.com/19
[Label Noise] Mix-Up 기법
데이터의 라벨이 잘못 부여된 경우에 대해서도 기존 학습 방법보다 대처가 가능한 Mix-Up에 대해 짧게 알아보려고 한다. VRM principle : 기존 ERM과 달리, 훈련 데이터셋만 학습하는 것이 아닌 훈련 데
shshin9812.tistory.com
이를 코드로 구현해보자.
먼저 임의로 rp1, rp2를 정의하여 1부터 batchsize 사이 값을 랜덤하게 골라 두가지 데이터를 mix 해준다.
아래의 식을 코드로 구현하기 위해 먼저 beta distribution으로부터 추출한 lambda 값을 정의하자.
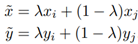
mixup 기법을 사용할시, a 변수를 beta distribution을 이용하여 정의 해주고 이를 b와 c로 나누어 각각 input과 target을 위한 lambda 값으로 정의한다.
두가지 데이터를 상수값과 곱하여 더해주어 input_shuffle과 target_shuffle 데이터를 생성해주어 mixup 기법을 이용한 새로운 data를 정의한다.
def shuffle_minibatch(inputs, targets, mixup=True):
batch_size = inputs.shape[0] # input dim
print(batch_size)
rp1 = torch.randperm(batch_size)
# rp1 is a random permutation of intergers from 1 to batch_size without repeating elements
inputs1 = inputs[rp1]
targets1 = targets[rp1] # torch.size([128])
targets1_1 = targets1.unsqueeze(1) # torch.size([128,1])
rp2 = torch.randperm(batch_size)
inputs2 = inputs[rp2]
targets2 = targets[rp2]
targets2_1 = targets2.unsqueeze(1) # into (row,1)
y_onehot = torch.FloatTensor(batch_size, num_classes)
y_onehot.zero_()
targets1_oh = y_onehot.scatter_(1, targets1_1, 1) # .scatter_(dim, index, src)
y_onehot2 = torch.FloatTensor(batch_size, num_classes)
y_onehot2.zero_()
targets2_oh = y_onehot2.scatter_(1, targets2_1, 1)
if mixup is True:
a = numpy.random.beta(1, 1, [batch_size, 1]) # beta distribution
else:
a = numpy.ones((batch_size, 1))
# a[..., None, None] = (128,1) -> (128,1,1,1) to 4 dim
# lambda
b = numpy.tile(a[..., None, None], [1, 3, 32, 32]) # numpy.tile(A,reps) Construct an array by repeating A the number of times given by reps.
inputs1 = inputs1 * torch.from_numpy(b).float()
inputs2 = inputs2 * torch.from_numpy(1 - b).float()
# lambda
c = numpy.tile(a, [1, num_classes])
targets1_oh = targets1_oh.float() * torch.from_numpy(c).float() # multiply weights
targets2_oh = targets2_oh.float() * torch.from_numpy(1 - c).float()
inputs_shuffle = inputs1 + inputs2
targets_shuffle = targets1_oh + targets2_oh
return inputs_shuffle, targets_shuffle
3. PENCIL
마찬가지로 아주 간단하게 블로그에 PENCIL 에 대해 정리해놓은 글이다. 더 많은 내용은 논문을 참고하면 좋을 것 같다!
논문 : PENCIL Deep Learning with Noisy Labels , https://arxiv.org/pdf/2202.08436.pdf
blog 주소 : https://shshin9812.tistory.com/20
[Label Noise] PENCIL 기법
데이터의 라벨이 잘못 부여된 경우에 대해서도 기존 학습 방법보다 대처가 가능한 PENCIL에 대해 짧게 알아보려고 한다. 기존 method와 달리 PENCIL은 clean 데이터셋과 같은 label noise으로 학습을 하기
shshin9812.tistory.com
먼저, PENCIL을 구현하기 위해서는 각 epoch마다 loss function이 다르게 정의됨을 알아야하고 pencil learning에서 매번 y_tilde를 back-propagation을 사용하여 update 해야 한다. 따라서 이 매 epoch마다 update된 y_tilde를 저장하고, 저장된 y_tilde를 불러와야한다. 이 3가지를 유의하여 코드를 작성해보자.
먼저 epoch마다 compatibility loss, classification loss, entropy loss 를 식을 코드로 구현한 것이다. 첫번째 stage1은 논문에서와 같이 70까지 정의하였고, stage1에서는 loss function을 lc(classification loss)를 사용한다.
# loss
if epoch < args.stage1:
# lc is classification loss
lc = criterion(output, target_var)
# init y_tilde, let softmax(y_tilde) is noisy labels
onehot = torch.zeros(target.size(0), 100).scatter_(1, target.view(-1, 1), 10.0)
onehot = onehot.numpy()
new_y[index, :] = onehot
else:
yy = y
yy = yy[index,:]
yy = torch.FloatTensor(yy)
yy = yy.cuda(non_blocking = True)
yy = torch.autograd.Variable(yy,requires_grad = True)
# obtain label distributions (y_hat)
last_y_var = softmax(yy)
lc = torch.mean(softmax(output)*(logsoftmax(output)-torch.log((last_y_var))))
# lo is compatibility loss
lo = criterion(last_y_var, target_var)
# le is entropy loss
le = - torch.mean(torch.mul(softmax(output), logsoftmax(output)))
if epoch < args.stage1:
loss = lc
elif epoch < args.stage2:
loss = lc + args.alpha * lo + args.beta * le
else:
loss = lc
아래 코드는 stage2 인 pencil learning에서 아래 식과 같이 lambda 를 사용하여 새로운 y_tilde를 update해주는 과정이다.
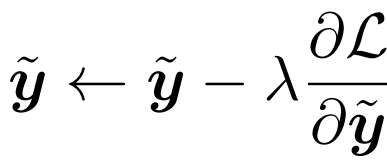
if epoch >= args.stage1 and epoch < args.stage2:
lambda1 = args.lambda1
# update y_tilde by back-propagation
yy.data.sub_(lambda1*yy.grad.data)
# update new_y (index)
new_y[index,:] = yy.data.cpu().numpy()
이는 stage2 (pencil learning) 까지 매 epoch마다 저장된 new_y를 부를 수 있게 저장한다.
if epoch < args.stage2:
# save y_tilde
y = new_y
y_file = args.dir + "/y.npy"
np.save(y_file,y)
y_record = args.dir + "/record/y_%03d.npy" % epoch
np.save(y_record,y)그리고 이를 아래와 같이 y_file이 존재 할경우 저장된 y값을 매 epoch마다 불러온다.
# load y_tilde
if os.path.isfile(y_file):
y = np.load(y_file)
else:
y = []4. Graph
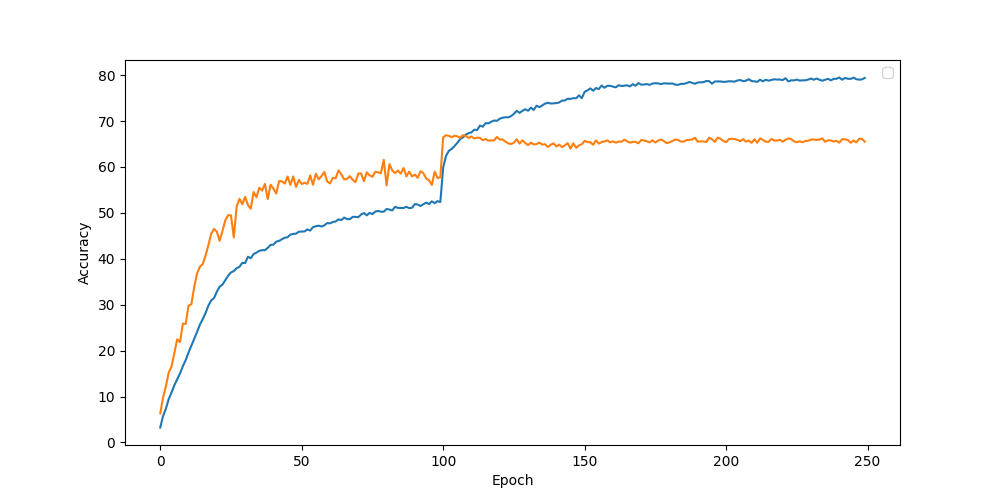
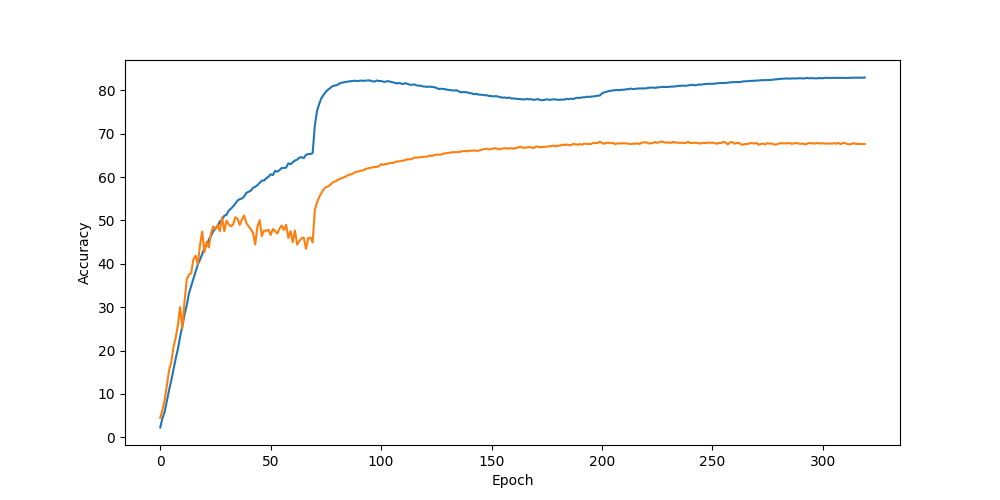
'코드 구현 및 오류' 카테고리의 다른 글
| [논문 구현] Learning both weights and connections for efficient Neural Network (0) | 2022.06.02 |
|---|---|
| [논문 구현] MobileNetV2 논문 구현 (0) | 2022.04.17 |
| [코드 오류] LiteHRNet 설정 오류 (0) | 2022.04.11 |


댓글