https://arxiv.org/pdf/1703.06870.pdf : Mask R-CNN
논문을 바탕으로 작성하였다.
Mask R-CNN
Instanace Segmentation은 이미지 내에 존재하나는 모든 객체를 탐지하는 동시에 각각의 경우를 정확하게 픽셀 단위로 분류하는 task이다.
Preview

Faster R-CNN의 RPN에서 얻은 RoI에 대하여 객체의 class를 예측하는 classification branch, bbox regression을 수행하는 box regression branch와 평행으로 segmentation mask를 예측하는 mask branch를 추가한 구조를 가진다.
→ Mask branch는 각각 RoI에 작은 크기의 FCN이 추가된 형태이다.
Segmentation의 효과적인 수행을 위해 객체의 spatial location을 보존하는 RoIAlign layer를 추가한다.
Mask branch

Mask R-CNN은 두 branch와 parallel하게 segmentation mask를 예측하는 mask branch가 추가된 구조(실제 구조와 달리 대략적으로 추가된 거에만 초점을 두어 그려진 그림)이다. RoI pooling으로 얻은 고정된 크기의 feature map을 mask branch에도 입력하여 segmentation mask를 얻는다.
Segmentation task는 pixel 단위로 class를 분류하기 때문에 detection보다 더 정교한 spatial layout (공간에 대한 정보)가 필요하다. 따라서 mask branch는 여러개의 convolution layer로 구성된 구조를 띈다.

Mask branch는 각각 RoI에 대해 class별로 binary mask를 출력한다. Mask R-CNN은 class 별 mask 생성 후 pixel이 해당 class에 해당하는지 여부를 위와 같이 (대략적으로 표현한 것) 표시한다.
Mast branch의 output dimension은 Km^2으로 K 는 classes개 개수를, m은 K binary masks of resolution m × m 에서 feature map의 크기를 의미한다.
RoIAlign
Detection의 RCNN 시리즈에서 사용했던 RoI Pooling은 pixel mask 예측에는 부정적인 결과를 보인다.

위 RoI Pooling은 quantization 과정을 수반하기 때문에 misalignment를 유도한다고 본다. 여기서 quantization은 실수 입력값을 정수와 같은 이산 수치로 제한하는 방법으로, 위 사진과 같이 하늘 색 부분의 data를 제외하게 되어 RoI pooling으로 얻은 feature와 RoI 사이가 어긋나는 misalignment가 발생한다.
따라서 본 논문은 이를 개선한 RoIAlign을 제안한다.
< RoIAlign 동작 >

1. RoI projection 으로 통해 얻은 feature map을 quantization 과정 없이 사용
2. Feature map 크기에 맞게 projection 된 feature map 분할 - 녹색선 (3x3 등분 → 3x3 feature map 생성을 위해)
3. 분할된 하나의 cell에서 4개의 sampling point 찾기 ( 이는 cell의 h,w 각각 3등분 하는 점이다)
4. Bilinear interpolation을 적용하여 4개 sampling point 찾기


5. 1개의 cell안에 4개의 sampling point에 대해 max pooling을 수행
따라서 RoI pooling의 하늘색 부분과 같이 정보를 잃는 경우를 없애준다!
→ 이로써 더 정확한 spatial location 보존이 가능하다. Mask Accuracy ↑

Loss Function
Mask R-CNN은 class branch와 mask branch를 분리하여 class 별로 mask 생성 후 binary loss를 구한다.
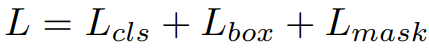
L_mask는 mask loss로 binary class entropy loss 이다. Mask branch에서 출력한 km^2 크기의 feature map의 각 cell에 sigmoid function을 적용한 후 loss를 구한다. L_mask 외 다른 loss들은 Faster-RCNN과 통일하다.
Mask R-CNN

위그림에서 이미지 전처리 과정을 거치고 RPN을 통해 얻은 Region proposal 중 최적의 RoI를 선정하게 된다.
1. objectness score가 높은 top-k개의 anchor를 선정. 학습 시 k=12000로 설정
2. bbox regressor에 따라 anchor box의 크기를 조정
3. 이미지의 경계를 벗어나는 anchor box를 제거
4. threshold=0.7로 지정하여 Non maximum suppression을 수행
5. 지금까지의 과정은 각각의 feature pyramid level별({P2, P3, P4, P5, P6})로 수행. 이전 과정까지 얻은 모든 feature pyramid level의 anchor box에 대한 정보를 결합(concatenate)
6. 마지막으로 결합된 모든 anchor box에 대하여 objectness score에 따라 top-N개의 anchor box를 선정. 학습 시 N=2000로 설정
그림에서 알 수 있듯 최종적으로 수많은 anchor box 중에서 최적의 N개의 box만이 학습에 사용된다. 그리고 RoIAlign을 통해 얻은 7x7 feature map을 mask branch에 전달한다.
Mask R-CNN Backbone

All convs are 3×3, except the output conv which is 1×1, deconvs are 2×2 with stride 2, and we use ReLU [31] in hidden layers
Conclusion


reference : https://jonathan-hui.medium.com/image-segmentation-with-mask-r-cnn-ebe6d793272 (Mask R-CNN review)
image reference : Understanding Region of Interest - Part 2 (RoI Align) https://erdem.pl/2020/02/understanding-region-of-interest-part-2-ro-i-align https://alittlepain833.medium.com/simple-understanding-of-mask-rcnn-134b5b330e95 (Mask R-CNN 사진)
https://herbwood.tistory.com/20 (Mask R-CNN 논문 리뷰)
https://kharshit.github.io/blog/2019/08/23/quick-intro-to-instance-segmentation
댓글