[Label Noise] PENCIL 기법
데이터의 라벨이 잘못 부여된 경우에 대해서도 기존 학습 방법보다 대처가 가능한 PENCIL에 대해 짧게 알아보려고 한다.
기존 method와 달리 PENCIL은 clean 데이터셋과 같은 label noise으로 학습을 하기 위해 사전에 추가로 필요한 정보가 없다. PENCIL의 main 아이디어는 PENCIL에서는 역전파를 통해 라벨 분포를 업데이트해주고 반복적으로 image label을 correct 한다.


Compatibility Loss : label에는 noise도 있지만, correct 한 label도 있으므로 라벨 distribution이 noise가 들어있는 labels와 완전히 다르지 않게 하도록 compatibility loss를 사용한다.
Classification Loss : 라벨 distribution을 update 한 값을 사용하는 loss function이다. 이는 gradient 값을 이용하여 라벨 distribution을 update 할 수 있도록 inverse KL-divergence를 사용한다.
Entropy Loss : f(x, θ) 와 라벨 distribution이 같아지게 되어 update 과정이 멈추는 것을 방지하기 위해서 regularization term으로써 Entropy Loss를 사용한다. 이 Loss는 하나의 class 값에 대해 peak할 수 있도록 도와주는 역할을 해준다.
따라서 최종 PENCIL loss는 다음과 같다.

PENCIL training 3 Steps
Backbone learning : backbone network를 먼저 noisy label에 overfit 되지 않게끔 높은 learning rate 을 설정하여 학습시켜 준다. 이때 loss는 cross-entropy loss function을 사용한다.

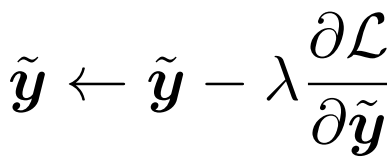
Final fine-tuning : 마지막으로 학습된 label 분포와 Classification Loss ( a, b = 0 )인 classification loss를 사용하여 network를 fine-tune 해준다. 이 과정에서는 label 분포는 더 이상 update하지 않으며 learning rate만 서서히 줄어드는 형식으로 진행된다.