[코드 오류] LiteHRNet 설정 오류
https://github.com/HRNet/Lite-HRNet github 코드를 바탕으로 학습을 하며 생긴 모든 오류들에 대해 작성해보고자 한다. 먼저 이해가 되지 않았던 부분에 대해서 정리해보면..
github train/test 작성 방법
처음에 python tools/train.py로 학습을 시작하는 방법이 아닌 새로운 방법을 보게 되어 낯설었다.
아래 그림과 같이 train with a single GPU 같은 경우 python tools/train.py 이지만, train with multiple GPUs 같은 경우 ./tools/dist_train.sh 로 시작해서 헷갈렸다.
Training
# train with a signle GPU
python tools/train.py ${CONFIG_FILE} [optional arguments]
# train with multiple GPUs
./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
Training on COCO train2017 dataset
./tools/dist_train.sh configs/top_down/lite_hrnet/coco/litehrnet_18_coco_256x192.py 8
Training on MPII dataset
./tools/dist_train.sh configs/top_down/lite_hrnet/mpii/litehrnet_18_mpii_256x256.py 8
sh 파일은 명령어가 여러줄인 script이며,

multi gpu로 학습하려면 세팅하는 것을 여러 명령어로 해야하는데 편리성을 위해 dist_train (distributed train).sh file을 만들어 실행하는 것이다.
변수들은 argument로 받으며, $1 과 $2가 argument 즉, CONFIG와 GPUS가 arguments들이다.
${CONFIG_FILE} 이 $1, ${GPU_NUM} 이 $2 가 되는 것이다.
따라서, coco dataset을 사용하는 경우
./tools/dist_train.sh configs/top_down/lite_hrnet/coco/litehrnet_18_coco_256x192.py 8${CONFIG_FILE} 자리에 위치한 다음 코드는 config file의 file path이고,
configs/top_down/lite_hrnet/coco/litehrnet_18_coco_256x192.py${GPU_NUM} 자리에 위치한 숫자 8 은 gpu 의 개수를 알려주는 args이다.
Errors
github Installation을 따라 보면, mmcv/mmcv-full 을 install 요구한다.
자칫 잘못하여 두개를 동시에 install 하게 되면 ModuleNotFound Error 발생을 일으키기 때문에 하나만 install하는 것을 권장하는데, 나는 mmcv-full만 설치했음에도 불구하고 ModuleNotFound Error가 발생했다.
InstallationThere are two versions of MMCV:
mmcv-full: comprehensive, with full features and various CUDA ops out of box. It takes longer time to build.mmcv: lite, without CUDA ops but all other features, similar to mmcv<1.0.0. It is useful when you do not need those CUDA ops.
Note: Do not install both versions in the same environment, otherwise you may encounter errors like ModuleNotFound. You need to uninstall one before installing the other. Installing the full version is highly recommended if CUDA is available.
그 이유로는 아래 그림과 같은데,

Pytorch를 1.x.0 version 설치를 요구했으나, 나의 pytorch는 1.10.2 였기에 자꾸 1.10.2에 맞는 실행 코드를 작성했던 것이다.
다시 가상환경을 세팅하여 pytorch version을 1.9.0으로 바꿨지만, pip list 를 실행했을때나 print(torch.__version__) 을 했을때,

1.10.2 version이 나오는 것이었다.
conda list 에서는 pytorch 가 1.9.0 이었지만 pip list 에서는 1.10.2 가 나온 이유로는,
pip install -r requirement.txt를 하는 과정에서 pip install torch, torchvision이 실행됐기 때문이다.


따라서 이를 모두 주석처리하고 실행하거나, mmcv-full을 pip install 통해 설치받고, 주석처리한것을 취소하면 정상적으로 작동이 된다!
그런데 진짜 문제는 여기서부터 였다..
NoModuleFound error가 mmcv 와 mmcv-full의 충돌때문이 아니었다는 사실..

train.py python file은 tools라는 directory에 있는 파일이고, models는 밖에 있는 폴더이기 때문에 그 위 폴더의 path를 연결해주는 코드가 필요한 것이다.
따라서
import sys
sys.path.append('/home/suhyun/Lite-HRNet')를 통해 models directory의 위의 폴더 경로를 추가해주면 error가 사라진다..!!!

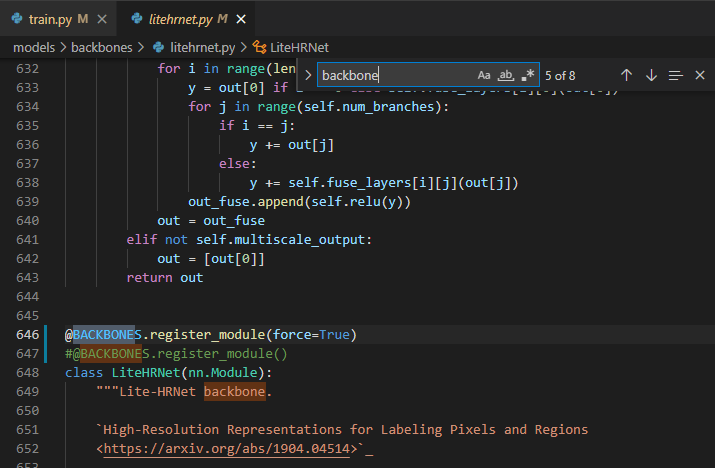
다음은 KeyError이다.
KeyError: 'LiteHRNet is already registered in models'
error를 타고타고 들어가보면, model 딕셔너리에 모델을 추가할 때 이미 있으면 에러는 내는 코드였다. 따라서 강제로 추가하려면 force= True 를 추가해주면 된다!
다음 에러 같은 경우, TopDownSimpleHead 은 더 이상 사용되고 있지 않는 이름이기 때문에 에러가 발생하므로,
KeyError: "TopDown: 'TopDownSimpleHead is not in the models registry'"Change the config file 'TopDownSimpleHead' to 'TopdownHeatmapSimpleHead',the name of 'TopDownSimpleHead' is deprecated
config file 을 'TopDownSimpleHead'에서 'TopdownHeatmapSimpleHead' 로 변경해주면 된다!
다음은 FileNotFoundError 이다. 말그대로 file이 존재 하지 않는다는 에러인데,
FileNotFoundError: TopDownMpiiDataset: file "/Lite-HRNet/configs/_base_/datasets/mpii.py" does not exist https://github.com/open-mmlab/mmpose/tree/master/configs/_base_/
github에서 configs/_base_/ 파일을 config directory 아래에 가져오면 해결!!