[논문 리뷰] Human Pose Estimation for Real-World Crowded Scenarios
https://arxiv.org/pdf/1907.06922.pdf Human Pose Estimation for Real-World Crowded Scenarios 논문을 참고하여 작성하였습니다.
Abstract
본 논문은 crowded people에 대한 human pose estimation 이다. Crowded people estimation의 어려운점이 있다면,
- 물체와 사람의 맞물림(occlusion)으로 인해 사람의 몸이 안보이는 경우
- 환경으로 인해 부분적으로 보이는 경우
이를 해결하기 위해 여러 방법이 쓰인다.
- 몸 일부 중 맞물린 부분을 명쾌하게 detect하기
- Synthetic Generated dataset JTA의 사용 (data extension)
1 Introduction
여태까지 나온 논문들은 uncrowded people pose estimation에 관해 연구를 진행했다. 본논문은 아래 사진과 같이 CCTV를 통해 얻은 사진의 장면을 pose estimation 하는 것을 목표로 한다.

위와 같은 사진은 물체나 사람끼리 맞물려서 몸의 일부분만 보이는 경우와 CCTV와의 거리로 인한 낮은 해상도라는 문제점이 존재한다.
본 논문에서는 다양한 방법으로 evaluation을 진행한다.
Evaluate the impact of a recently proposed occlusion data augmentation method on highly crowded data. We then propose our own architecture modification for explicitly modeling occluded keypoints within a CNN pose detector. And finally, we generate a new simulated dataset, which is specifically suited to evaluate recent pose detection methods under crowded surveillance scenario conditions.
위 내용과 같이, 최근에 생성된 data augmentation method 가 crowded data 에 끼치는 영향을 평가하고, 맞물린 keypoints들을 명확하게 잡아내는 CNN pose detector 구조를 제안한다. 마지막으로 new simulated 데이터를 생성하여 이를 사람들이 밀집된 환경에서 recent pose detection methods 을 평가한다.
2 Related Work
Top-Down and Bottom-Up Methods
Human pose estimation에는 bottom-up, top-down method 2개가 존재하는데, top-down의 경우는 사람을 먼저 detect하고 각 사람별로 keypoints들을 identify하는데 사람을 detect하는 각 bounding box에는 keypoint class 당 1개의 keypoint를 지닌다.
Further Work on Crowd Pose Estimation
JCSPPE라는 evaluation method를 사용하는데, joint의 후보를 서로다른 score로 매기고 heatmap에 적용한다. Joint association algorithm을 이용하여 이 결과를 사용해 person-joint connection graph를 생성해준다. 이에 따라 best joint association을 찾는다.
COCO dataset은 CCTV와는 다르게 not too crowded 한 data이기 때문에 dataset을 생성하게 된다. 그 중 crowded dataset을 생성한 https://arxiv.org/pdf/1803.08319.pdf : Learning to Detect and Track Visible and Occluded Body Joints in a Virtual World의 dataset이 본 논문이 사용하고자하는 dataset과 가장 유사하다.
3 Methods
Crowded pose estimation을 최적화 하기 위해 다양한 method를 사용했는데 https://arxiv.org/pdf/1804.06208.pdf : Simple baselines for human pose estimation and tracking 에서 사용한 single-person pose esimator을 본 논문에서도 적용한다. 이 method는 2가지의 stage를 가지는데, 첫번째로는 object을 detect하여 person을 localize하고, 두번째 step으로는 single-person pose estimation을 각 detected된 사람마다 해준다.
Crowded scenes를 위해 data augmentation methods를 사용하는데 이는 uncrowded, crowded scene에서의 pose estimation 성능을 높여주는 역할을 해준다.
또한, baseline 구조는 JTA dataset과 구조 extention을 통해 맞물려진 keypoints를 잘 detect한다.
Synthetic Generated Occlusions
인위적으로 맞물려진 data를 만들어 성능을 높이려고 하는데, data가 부족하여 instance segmentation label이 제공된 COCO dataset을 사용한다. COCO dataset에서 랜덤하게 object을 고르고 이를 segmentation을 이용하여 cut out 작업 과정을 거친다. 이후 bounding box 안에 약 8%~70%(bounding box의 8~70%) 사이즈로 붙여 넣어준다. Bounding Box 안에 사람 위에 정확히 얹혀졌을 때 faulty training data를 발생하기 때문에, body parts만 scence에 넣어주는 방법과, 경계선 안에서만 위치 할 수 있게끔 조정해준다.
Occlusion Detection Networks

사용한 구조는 위와 같다. 첫번째 구조는 OCCNet이며, 2개의 transposed convolution을 이전에 joint representation을 학습하고 이를 지나면 split 하여 occluded keypoints와 visible keypoints 두개의 결과를 내놓는다.
두번째 구조는 OCCNetCB이며, transposed convolutions 1개를 지나 2개로 split 된 후 2개의 layer가 서로 정보를 교환하는 형태를 가진다.
Pose 마다 2개의 heatmap를 output으로 갖는데, 1개는 visible keypoint에 대한 결과와 나머지는 occluded keypoints에 대한 결과이다.
Loss function
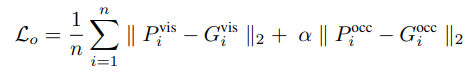
따라서 loss function은 2개의 heatmap의 loss를 계산한 방식으로, 다음과 같이 visible한 keypoint와 occluded keypoint 에 대한 prediction 과 ground truth의 MSE 합으로 식이 구성된다. a는 weighting factor로 학습 데이터에서 occluded keypoint의 영향을 줄이기 위해 사용된 파라미터이다.
JTA-Ext
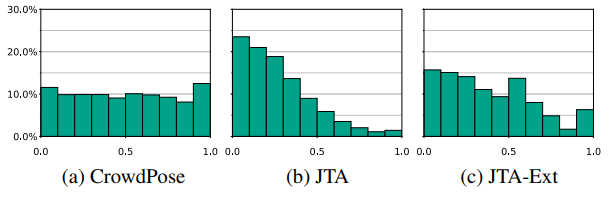
JTA data는 게임 상 캐릭터의 pose를 지닌 데이터로, 위 표를 보면 알 수 있듯 CrowdPose보다 제한적인 pose를 지니며 역동성이 낮은 것을 확인할 수 있다. 따라서 이를 해결하기 위해 JTA-Mod에서 더 다양한 동작을 가진 데이터를 가져와 JTA extended 버전인 JTA-Ext를 생성했다. 이를 통해 더 역동적이고 밀집된 사람 데이터를 얻을 수 있었다.
4 Experiments
두개의 데이터셋을 모델에 적용하였는데, 20,000 image를 지니고 80,000개의 pose와 14개의 keypoint를 가진 CrowdPose 데이터셋과 Grand Theft Auto V 비디오 게임에서 가져온 22개의 keypoint를 지닌 JTA 데이터 셋을 사용한다.
Evaluation Metrics
OKS는 2개의 pose의 유사성을 측정하는데, IoU와 비슷한 방식으로 keypoint들끼리의 overlap을 바탕으로 계산한다.
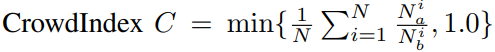
N은 사진속 사람의 개수이고 분모의 값은 i 번째 사람에 해당되는 bounding box 안에 해당 사람의 keypoint의 개수, 분자 값은 i 번째 사람의 bounding box 안에있는 j ( ≠ i ) 번째 사람의 keypoint 개수이다. 이에 따라 level은 0~0.1로 easy, 0.1~0.8로 medium, 0.8~1.0 hard로 나뉜다.

위 사진과 같이 높은 시점에서 내려다 본 (CCTV로 본 사진(b)) 같은 경우 crowdness를 높게 측정하지 않는 것을 알 수 있다. 낮은 시각에서 촬영한 (a) 보다 overlap 점수를 낮게 부여하는 특성이 있어 (a)는 CrowdIndex가 0.91, (b)는 CrowdIndex가 0.69이다.
Implementation
Baseline model로 pre-trained 된 ResNet50을 backbone 으로 적용한 https://arxiv.org/pdf/1804.06208.pdf : Simple baselines for human pose estimation and tracking 을 사용한다. 평가의 공평성을 위해 person detection은 AlphaPose에 통합되어있는 YOLOv3를 사용한다.
Q. AP?
정밀도(Precision)은 예측된 결과가 얼마나 정확한지를 나타내는 지표로, 검출된 것들 중에서 정답을 맞춘 것들의 비율이 어느정도인지를 알 수 있다. 따라서 검출 결과의 정확도를 판단한다.
재현율(Recall)은 GT중에서 얼마나 정답을 맞추었는지를 나타낸다. 따라서 검출되어야할 객체들 중에서 제대로 검출된 것을의 비율을 의미한다.
정밀도와 재현율은 반비례 관계를 가진다. 이 둘을 모두 고려하고 정확도를 평가하는 것이 가장 옳은 방법인데, 이를 이용한 개념이 precision-recall 곡선 및 AP(Average Precision)이다.
AP는 Recall을 0부터 0.1 단위로 증가시켜 총 1까지 (11개의 Recall 값) 증가 시킬 때 Precision이 감소하게 되는데 각 단위마다 Precision 값을 계산하여 평균을 내어 계산한다. 따라서 11가지의 Recall 값에 따른 Precision 값들의 평균을 AP라고 한다. 하나의 class 마다 AP 값을 계산할 수 있고, 전체 class 개수에 대해 AP를 계산하여 평균 낸 값이 mAP이다.
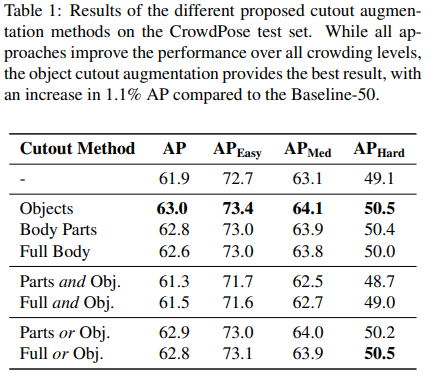
CrowdPose test에 cutout augmentation method를 적용한 결과이다. Cutout method를 통해 성능이 증가한 것을 확인할 수 있으며, 이 중 object cutout augmentation이 가장 좋은 결과를 보여주었다. 또한, Full body cutout을 적용한 결과가 body part를 적용한 결과보다 낮다.

Table2의 결과를 확인해보면 사실상 occluded keypoint와 visible keypoint에 차이를 두어 모델을 만드는 것은 성능에 큰 영향을 끼치지 않는 것을 확인 할 수 있다.

Figure6에서 보이듯 OCCNetCB가 visible keypoint(초록색), occluded keypoint(빨간색)을 잘 구분하여 나타내는 것을 볼 수 있다. 그러나 crowded scenarios에서 특별히 이점을 주는 경우가 없어 Baseline-40을 사용하는 것이 가장 좋은 성능을 띄는 것을 확인 할 수 있다.
Synthetic Training Data
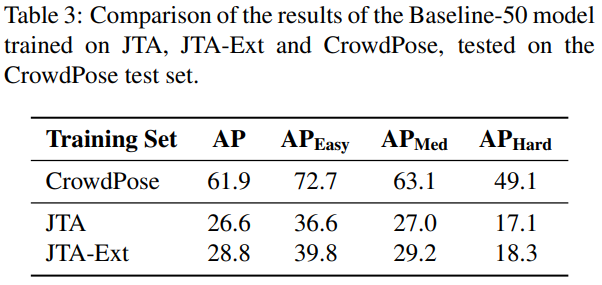
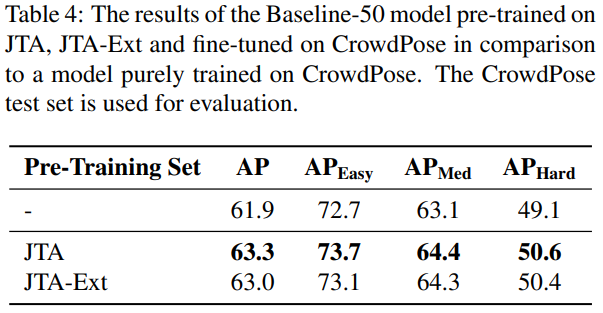
Table3과 Table4를 통해 모델이 CrowdPose 에 finetuned 해주면 synthetic data의 사용이 모델 성능을 높여주는데 기여하나, synthetic data 하나만 사용하면 모델의 성능이 낮아지는 것을 알 수 있다. 따라서 real-world에 적용할 때 JTA, JTA-Ext와 같은 synthetic data 하나만으로 사용하면 좋은 성능을 낼 수 없다.
5 Conclusion
COCO object을 data augmentation 통하여 추가하였을때 성능이 높아지는 것을 확인할 수 있었다. 그러나 body parts나 person instances를 추가하였을때는 덜 효율적이었다. Crowd-level pose estimation에서 JTA data의 추가가 이점을 가져오는 것을 알 수 있었으며, 이 데이터만을 이용하는 것에는 synthetic data와 real-world data간 domain gap으로 인해 한계점이 있다는 결론을 내릴 수 있다.
reference : https://eehoeskrap.tistory.com/546 (AP 개념)